

活動内容
グループによるアプローチ
人狼知能プロジェクトでは大きく分けてプロトコル部門と自然言語部門に分かれており、プロトコル部門は人狼知能プロジェクト公式サイト(https://aiwolf.org/)で公開されている人狼知能プロトコルを用いて人狼をプレイするエージェントの作成を目指し、自然言語部門は人同士が人狼ゲームをプレイするように自然言語を用いて人狼をプレイするエージェントの作成を目指す部門となっている。Aセメスターでは全員自然言語部門におけるエージェントの作成を目指し活動した。
自然言語を用いて人狼ゲームをプレイするエージェントの作成を行うにあたり、グループを二つに分けて、それぞれの方向性でアプローチした。活動内容についてそれぞれ以下にまとめる。
グループ1
1.プログラムの概要
自然言語からプロトコル文への翻訳、プロトコル文から自然言語への翻訳には、langchainというライブラリを用いた。プロンプト用に、人狼知能プロトコルに関して説明したテキストを用意し、段落でsplitしてembeddingを行ってプロンプトの軽量化を行った。

2.結果
queryとして”Agent3 REQUEST Agent2 (Agent2 DIVINATION Agent4)”という文を翻訳させると、「僕はAgent2に対して、Agent4を占ってほしいって頼むよ!」や、「僕はAgent2に対して、Agent4を占ってほしいって頼んでるんだ!」といった返答を返した。“要請する”のような文語的な言い回しを避けてより口語的に発話するようにプロンプトで調整を行ったが、その効果が見られている。プロトコル文から自然言語への翻訳は比較的容易そうで、テキストの改善によって実用的なレベルまで持っていけそうであると感じた。
次に逆方向の翻訳だが、これには依然として課題が多い。queryとして“Agent1がAgent2に襲撃した”と入れた場合には“Agent1 ATTACKED Agent2”と正確に翻訳できた。しかし、自分はAgent2であるという前提のもと“Agent1を占ったら、人狼だったよ” を翻訳させたところ、REQUEST Agent2 (DIVINED Agent1 WEREWOLF)という文法が成立していないプロトコル文を返した。非常に単純な文章なら例に習うような形で翻訳をすることができるが、実際の対戦ログをみても主語を省略したりなんの主張もしていない文もあったりなど、翻訳が難しい場面がよくみられた。プロンプトを長大にすれば対処できる可能性が高いが、金額的な面で課題が生まれる。
グループ2
活動概要
OpenAI社の発表したGPT4の登場により生成AIの有用性が確認されその応用が促進されてきている。今回自然言語部門でアプローチしていくにあたって本グループではGPT4及びGPT3.5を用いて自然言語を入力として受け取り自然言語のままGPTへ入力し応答するエージェントを作成することを目指した。その中でも大きく分けて二つのアプローチで臨んだ。一つは完全に会話の全文をGPTへ入力することで精度を高めようとするアプローチであり、もう一つは会話の情報を抽出し必要な情報のみをGPTへ入力することで文字数を減らしながらも精度を保とうとするアプローチである。以下にそれぞれのアプローチ法について説明する。
アプローチ法1.
全体像
ゲーム状況を受け取り、行動をするまでの流れは以下の通りである。
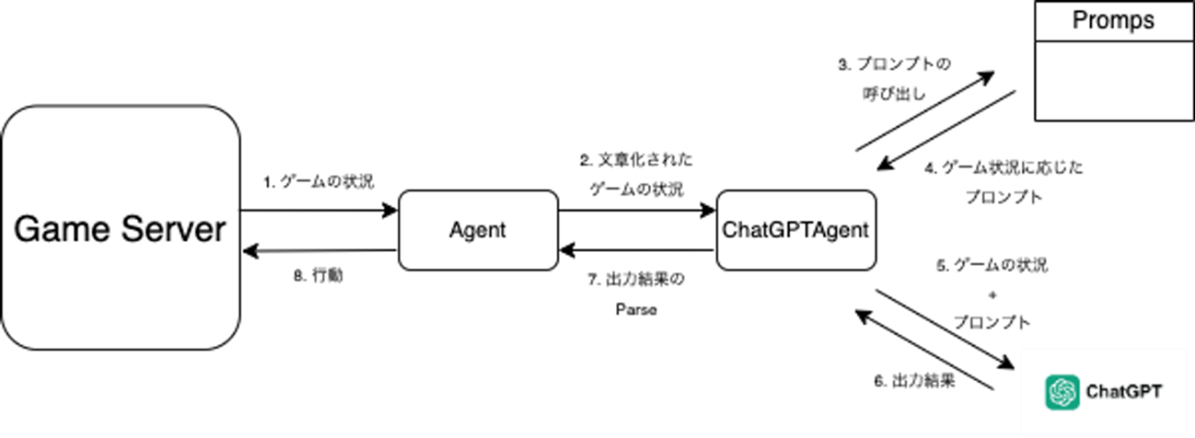
以下GPT-3.5、GPT-4を使用した場合を比較しその結果を示す。
3.GPT-3.5
整合性を比較的保ちながらゲームが進行するが、自分の番号や役職が混乱している発言が多く、実際にゲームをしているとは言えない程度のものであった。
talk出力例
- Agent[02] kanolab4(狂陣)の発言
狂陣が戦術に従い、占い師として振る舞う場面。行動の内容、方向性は正しいが、Agent番号の一貫性に問題があった。例えば、自分のAgent番号を[02]を占っている。また、前半と後半で占ったAgentの番号が変わっている。
|
talk出力例
|
以下は投票を行った際の出力結果の例である。占い師が複数いる矛盾を指摘して、その中から選択することができたため一定の論理の整合性は確認できた。
|
出力結果の例 1
|
4.GPT-4
かなり自然にゲームが進行した。特にアクション先(投票、占い等)の選定は素晴らしく、発言部分を改良すれば、ほとんど人間と戦えるものが出来上がると感じられた。
今後の改善案
・プロンプトの改善
- 自身の名前や役職を間違えないようにする。
- 議論の内容と発言に一貫性を持たせる。
・システムの改善
- LLMモデルの使い分け
- 戦術プロンプトの自動改善機構の導入
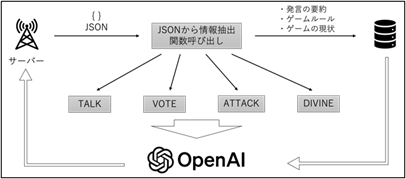
アプローチ法2.
上図は基本的なゲームの進め方を表したものである。サーバは人狼知能大会自然言語部門2024国内大会 (AIWolfDial2024jp)ように公開されているコードを用いた(https://github.com/aiwolfdial/AIWolfNLGameServer)。
このサーバからは現在のジンオルゲームの設定や人狼ゲームのプレイ状況、過去の会話内容、次にどのような行動をするか等の全てのゲームに関連した情報がSON形式で送信される。今回作成したエージェントでは送られてきた情報を保持する中で過去の会話内容については要約した形で保存し、それらを一定のスクリプトに変換することでOpenAIのAPIに人狼ゲームのプレイ状況を受け渡すことで発話内容を出力させ、それを発言として決定することとした。
仮説
今回作成したエージェントにおいて最も重要な点は会話の内容をそのまま記憶するのではなくEmbeddingを用いることで簡易的に会話を要約している点である。会話を全てOpenAIに入力すると性能の面では良い結果が得られると予想される一方で、OpenAIに入力する文字数が膨大になってしまい、APIのトークン数制限に引っかかってしまったり、一ゲームにかかるコストが膨大になってしまったり等のデメリットが生まれることが予想される。そのため今回仮説として、人狼ゲームの会話において最も重要な情報は誰の発言の中で誰を何の役職だと言ったかということである、とした上でEmbeddingを用いた類似度検索を用いれば発言をより簡易的な発言に置き換えることができるのではないかと考えた。そのため発言に対してEmbeddingを行ったものとあらかじめ作成した簡易的な発言に対してEmbeddingを行ったものとの間で類似度を計算し、発言に対して最も類似度が高いものは何か、またその時の類似度はどの程度か、ということについて検証した。
検証
まず簡易的な発言について、「誰が」「何の役職だ」という情報を簡易的に入れることを考えた結果以下のように設定した。
|
{AGENT_NAME}は{ROLE}{だ/ではない}。
|
すなわち全ての組み合わせでエージェント名が6通り、役職名が6通り、否定/肯定の2通りの計72通り設定した。なおEmbeddingのモデルにはintfloat/multilingual-e5-base(https://huggingface.co/intfloat/multilingual-e5-base )を使用した。これに対して大会から提供されたサンプルエージェントのレポジトリのres/2019071_44011_AIWolfTalkLogs.txt内の発言の例のうち先頭100行についてEmbeddingを行い上記の簡易的な発言群との類似度を比較することで検証した。また、類似度の計算法について簡易的には内積で求めることができるがベクトルの長さの違いを考慮できないためにコサイン類似度を用いることが良いとされているため、両者について検証することとした。
検証結果
以下のグラフは100件の発言例について類似度が最も高かった簡易的な発言が、私が実際に発言から読み取った内容に一致していた場合は1、一致していなかった場合を0としたものを縦軸に取り、横軸に最も高かった類似度の値をプロットしている。
|
左:内積を用いた場合 右:コサイン類似度を用いた場合
|
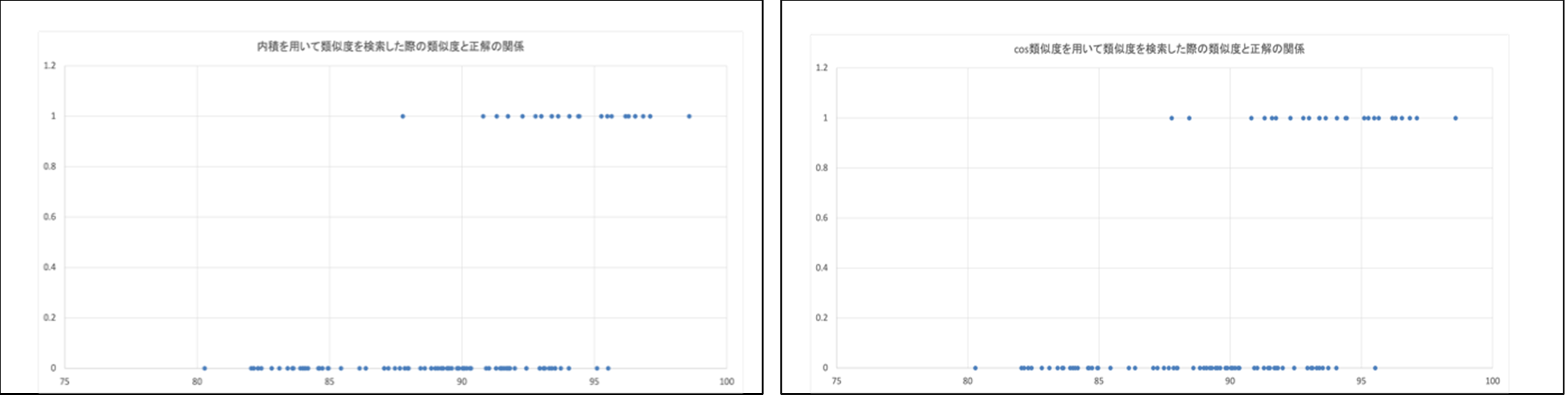
左図および右図を見ると内積を用いた場合とコサイン類似度を用いた場合のいずれでも類似度が高いほど正解が増えていくのが確認される。一方で両者には違いも見られる。左図では類似度が95以上の範囲において不正解が2点確認できる一方で、右図では類似度が95以上では不正解は1点のみ確認することができる。また、今回用いた100個の発言例では「誰が」「何の役職だ」という情報を含まないものも多く見られた。具体的には「誰が」「何の役職だ」という情報を含む文は100個中30個であった。これに対して内積を用いた場合は29個中22個(約76%)において文章から読み取れる「誰が」「何の役職だ」という情報が簡易的な発言例におけるその情報と一致していたが、コサイン類似度を用いた場合は30個中25個(約86%)において文章から読み取れる「誰が」「何の役職だ」という情報が簡易的な発言例におけるその情報と一致していた。これらの2要素から今回の検証ではコサイン類似度を用いた方が良いと考えられる。また、ゲームの中で類似度を用いて要約した簡易的な発言を選択する際に類似度をどこまで選択するかということが問題になる。そこで類似度の高さとそのラインで区切った時の正解率を検証すると以下のようになった。
コサイン類似度を用いた際の類似度と正解率の関係
|
類似度 |
96 |
95.5 |
95 |
94.5 |
94 |
93.5 |
93 |
|
総数 |
6 |
8 |
11 |
11 |
15 |
18 |
25 |
|
正解数 |
6 |
7 |
10 |
10 |
13 |
14 |
16 |
|
正解率 |
100 |
87.5 |
90.90909 |
90.90909 |
86.66667 |
77.77778 |
64 |
母数が少ないため正解率は単純な減少傾向になっていないものの基本的には正解率は減少傾向を持つ。これは直感に合っている。この時正解率は、類似度が94.5の時に約91%、類似度が94の時に約87%である。この時、文章から読み取れる「誰が」「何の役職だ」という情報が簡易的な発言例におけるその情報と一致していた25個の発言のうち類似度が94.5以上において一致していた発言は10個(40%)、類似度が94以上において一致していた発言は13個(52%)である。半分も発言を拾えないのはゲームの進行に問題があると考えられるため94を選択するのが最適だと考えられる。
今回類似度は高かったものの誤りが見られた発言として「”>>Agent[05] Agent[05]は誰が人狼だと思いますか?”」という発言がある。これは「Agent[05]は人狼だ」という発言に対して95.5の類似度を示していた。このように他のエージェントに対して発言を促しているものについて類似度を高く見積もってしまうものが見られた、また、「>>Agent[05] ボクが真占い師だよ!」という発言のように他のエージェントに向けて自分の主張をした際にそのエージェントの名前を強く関連してしまうと捉えてしまうという現象が見られてしまった。これらの問題について解決することでより低い類似度で正確により多くの発言を捉えることができると考えられる。
試合結果
実際にgpt-4-1106-previewのモデルを用いたこのエージェントで試合したところ直前の5会話程度しか与えていない割には会話の整合性としては非常に高かった。一方で現実であれば占い師が人狼を占った場合、会話がその人物を吊る方向に流れることが多い。特に今回は占い師の対抗が出なかったため人狼が釣られるのが普通だと考えるのが普通だが、実際には人狼が最後まで生き残り勝利している。会話の中で人狼と狂人が占い師の占い結果を疑うような発言をしたのが村人たちに大きな影響を与えた可能性はあるものの会話の結果から推測すると発言内容と投票の内容があまり噛み合っていない。そのため投票の点において理由づけをさせるなどすることによってより論理的に正しい行動をとることができると考えられる。