


活動内容
丸4日集中講義として開催し、AIの学習からFPGA実装までを行う。AIの学習にはGoogle Colaboratory、FPGAは画像認識に特化したXilinxのFPGA KV260を用いた。書学者が多いため、FPGAは簡単に設計を試せるよう、AIモデルの自動コンパイラと高位合成を基に設計を行った。回路レベルの最適化は難しいものの、通常1か月以上かかる回路実装を僅か半日で終わらせることが可能である。一方で、AIのモデル、学習技術、処理フローやメモリアクセスを最適化することによって、処理性能を大幅に向上することが可能である。過去のエッジAIコンテストの出題を題材として実習形式で学んだことにより、FPGA実装のノウハウを習得することが可能となった。最終日には企業との交流会を設け、設計報告と共に研究の最前線の活動を学んだ。
FPGA及びPCの台数に限りがあるため、15人ずつ3期にわけて実施。
1期:7月5日、8日、11日、18日 (初回のため、さらに人数を絞り実施)
2期:7月27日、28日、8月1日、2日
3期:8月3日、7日、8日、9日
学内最終報告会:8月21日
日立製作所中央研究所訪問:8月22日
各実施期間における実装内容
1日目:チュートリアルと演習
2日目:FPGA実装とAI処理高速化手法の検討、実装
3日目:FPGA実装
4日目:FPGA実装
最終報告会: 企業の研究所に訪問。学生から実装内容の報告と、企業研究者との交流を実施 2023年度は日立製作所中央研究所に訪問。FPGAや半導体集積回路分野の研究者との交流会や西澤CTO 常務執行役員の講演、矢野フェローによる講演を実施。


AIとFPGA開発の様子 開発フロー
受講者は各1台PCとFPGAを用いて自動運転を題材としたAI認識処理をFPGAに実装した。自動運転を題材とした認識処理は経産省主催AIエッジコンテスト第二回の過去問と同一であり、受講生が取り組みやすいようチュートリアル形式で行えるように、ステップごとに実装内容を明確化した“開発フロー“のテンプレートファイルを作成し配布した。受講生が行った開発フローを図37に示す。通常数か月要する工程であるが、テンプレート化により開発内容の明確化、それぞれ工数を短縮するために高位合成技術を随所に取り入れることで、4日間の期間内で何度も実装することが可能となった。


受講生はAI処理の精度と認識処理(フレームレート、FPS)を競うコンテスト形式で開発を進めた。マルチスレッド化、AIモデルの変換、画像切り出し、メモリアクセス処理等を最適化するように取り組ませた。C++やFPGAコードを細部にわたって開発することが必要なため、実装力の差により得られる結果が変わり、特に学部3年生はあまり開発やFPGAに触った経験がないため苦戦する様子が見られた。一方で、C++やFPGAコードをChat GPTを用いてコード生成し素早く実装、デバッグ作業を繰り返し優秀な成績を修めた学生も多くみられ、非常に斬新な取り組みが見られたことは評価に値する。
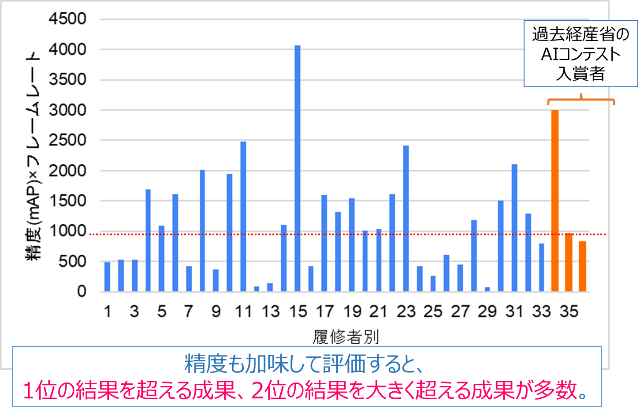
生成AIの新たな活用や熱心な取り組みの甲斐もあり、AIコンテスト開催時の成績に迫る結果が得られた学生が多くみられた(下図左)。特に認識精度と処理速度の双方を加味した指標の場合は、過去の経産省コンテスト優勝者よりも優れた性能が得られた受講生もいた(下図右)。過去のコンテスト優勝者の例では精度を相当に犠牲にして処理時間を短縮化する実装としていたが、今回の優勝学生は最新の研究成果を取り入れて、AIモデル及び学習手法にFPGA実装時における誤差を最小化する実装に取り組んだ。結果、非常に高い精度と短い実行時間の両立を達成し、非常に高い性能を実現できた。以上の成果は日立製作所中央研究所内で学生自身が発表報告し、西澤常務執行役員 CTOより表彰を受けた。


学生の声
●プロジェクトへ参加した動機
機械学習について、ソフトウェアにおける高速化手法とハードウェアにおける高速化手法のギャップが知りたかった。本プロジェクトでは、馴染みのある画像識別のタスクをFPGA上で動かし,その性能向上・高速化に取り組むことでHW・SW両面からのアプローチを試すことができた。
●プロジェクトでの取り組み
タスクとしては、車・バス・歩行者の3物体検出および分類に取り組み、識別性能の向上および処理速度の向上を行った。プロジェクトを進めることで、逐次画像識別を行うデモ動画を表示し、その性能と処理速度を検証することが可能である。下図右のデモのように識別した物体が赤枠で囲まれる動画が表示され、左のように各物体の識別性能を表示することができる。

●学んだ・ためになったこと
4日間という限られたプロジェクトであったが、初心者でもデモを動かせる設計になっており、またSW・HW両面における改良すべき点の多さから上級者も楽しめる設計でもあった。私はどちらかというと後者の立場から参加したが、改良すべき点が多い分、限られた時間で実装可能な手法を取捨選択する大切さを実感した。
例えばモデルの変更は誰しもが思いつく改良点だが、FPGAがモデルの演算をサポートしていない可能性や、学習パイプラインの実装コストが高いことから殆どの人が断念した(実際,最新版であるyolo v7は動かなかった)。一方、パイプライン処理は高い実装コストがありそうと敬遠されていたが、検証が容易なためデバッグのサイクルが短く、結果としてパイプライン処理+マルチスレッド化まで実装できた人が多く見られた。このことから、実装手法を取捨選択する具体的な方針として、実装だけではなく実装⇒検証のサイクルを見積もることが大切であると学んだ。
機械学習モデルのトレーニングからHW上での推論実装までを一気通貫で行うことで、全てのレイヤにおける高速化・性能向上について調べ考えることができ、自身の研究にとっても非常にためになるプロジェクトであった。